04
The chart the field can't draw
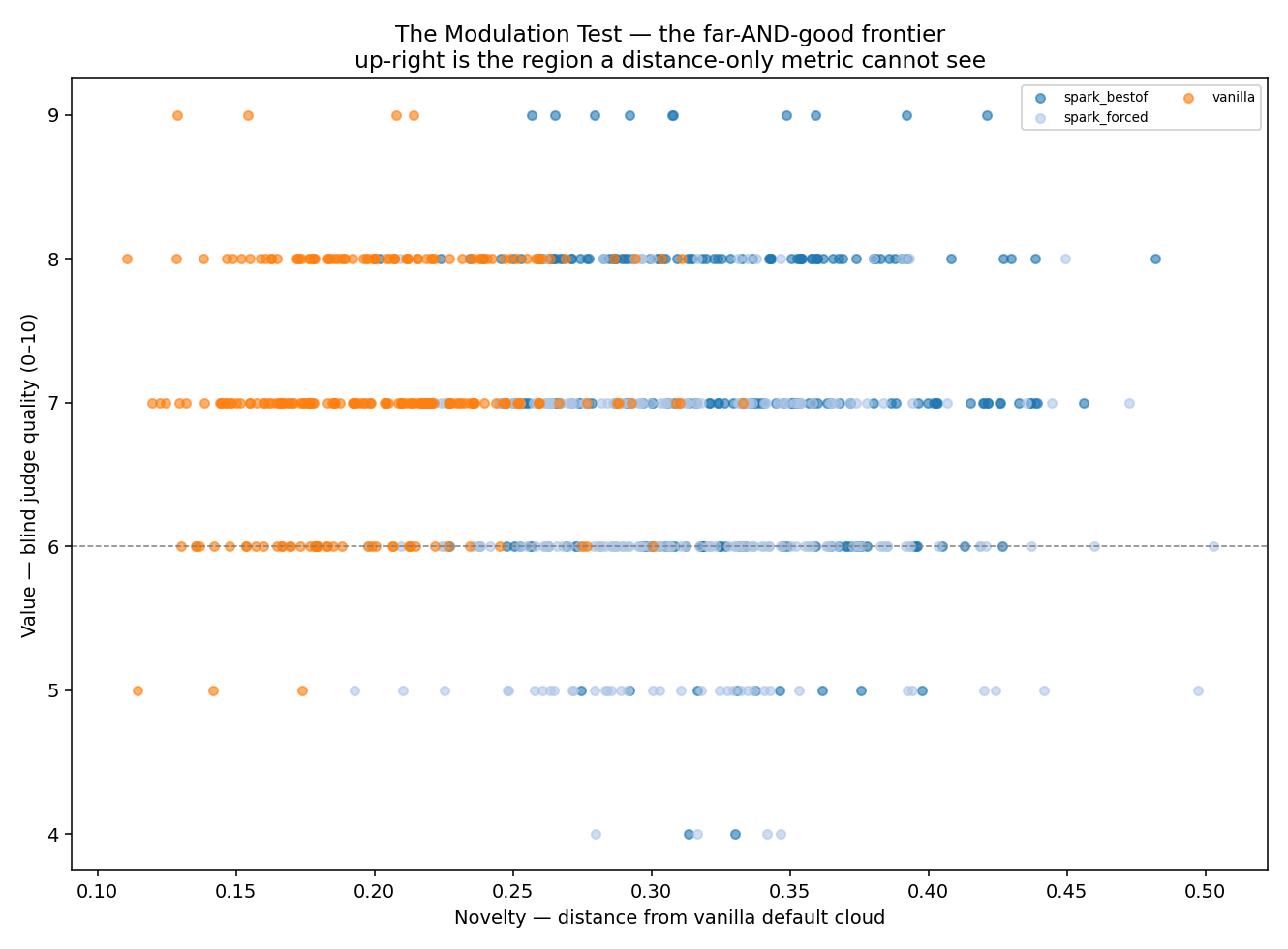
Each dot is one idea. x = novelty (distance from the
average), y = judged quality. The champion (dark) occupies the
up-right — far AND good. Plain forcing (light) reaches far but bleeds into the low-value band.
Existing work — including the strongest recent results — optimises a single number: distance from the default cloud. But distance without value is just weirdness.
The Modulation Test scores every idea on both axes and reports the far-and-good frontier — the region a distance-only metric is blind to. That is the difference between a randomness injector and a cognitive instrument. It is also the metric a competitor cannot retrofit without rebuilding their evaluation from the ground up.